
Martin Schmitt hat am 16. März 2020 erfolgreich seine Dissertation „Die Digitalisierung der Kreditwirtschaft. Computereinsatz in den Sparkassen der Bundesrepublik und DDR, 1957-1991“ an der Universität Potsdam mit magna cum laude verteidigt. Die Betreuer_innen der Arbeit, Prof. Dr. Frank Bösch (ZZF Potsdam) und Martina Heßler (TU Darmstadt) hoben in ihren Gutachten die Pionierarbeit hervor, die Schmitt für die Erforschung der Geschichte der Digitalisierung in der deutschen Wirtschaft mit großer Akribie geleistet hat. Als Endnote bewerteten sie die Dissertation mit einem guten magna cum laude.
Schlagwort-Archive: Software

Neu erschienen: Martin Schmitt – The Code of Banking
Oftmals werden wir auf Konferenzen gefragt, ob wir denn schon etwas aus dem Computerisierungs-Projekt veröffentlicht haben, auf dass man sich beziehen könne. Neben dem 2012 erschienen Heft in den Zeithistorischen Forschungen zur Geschichte der Informationsgesellschaft verweisen wir immer auf den programmatischen Artikel von Jürgen Danyel und Annette Schuhmann im Sammelband „Geteilte Geschichte„. Diese Woche kam nun ein weiterer Artikel hinzu, in dem unser Projektmitarbeiter Martin Schmitt den Schwerpunkt seiner Arbeit angeht: Software in Banken. Der Titel des Artikels lautet: „The Code of Banking. Software as the Digitalization of German Savings Banks„

Die Zukunft der Digitalgeschichte
Wohin entwickelt sich die history of computing? Und welche Rolle spielt dabei die Anfangszeit des Digitalen Zeitalters? Diese Frage stand im Zentrum eines kleinen Workshops in Siegen am vergangenen Wochenende (10.-12. Juni 2016). Organisiert von Thomas Haigh kamen hier Historiker/innen, Medienwissenschaftler/innen und Informatiker/innen aus ganz Europa zusammen, um über „Beyond ENIAC. Early Digital Platforms and Practices“ zu diskutieren.
VCFe in München
An diesem Wochenende findet in München das 17. Vintage Computing Festival Europe statt. Vom 30. April – 1. Mai gibt es dort die Möglichkeit, alte Computerhardware zu entdecken, mit deren Entwicklern ins Gespräch zu kommen und sich über historische Software auszutauschen. Schwerpunkt Thema ist diesmal „Computer als Beruf(ung)“. Unter anderem wird Stefan Höltgen einen Vortrag zur Medialität des Computers halten und Dirk Kahnert zeigen, wie sich ein Betriebssystem auf den alten DDR-Kleinrechner KC 85 portieren lässt.
Ersetzen Computer den Historiker? (Teil 1)
Plötzlich stehen auch die kreativen Berufe scheinbar zur Disposition. Sind jetzt auch die Historiker dran? Die Debatte darüber ist entbrannt. “Can computers replace historians?” fragt Rory Cellan-Jones in der BBC. Seine Antwort ist “Nein” – seine Frage aber Teil einer Debatte, die auch die Geschichtswissenschaft nicht unberührt lassen wird.
Der Computer ist für den Historiker ein nicht mehr wegzudenkendes Werkzeug. Geeignete Software ordnet Literatur und Archivmaterialen, mit Textverarbeitungsprogrammen werden wissenschaftliche Artikel und Monographien angefertigt und das Internet ist das Tor zu einer ungemeinen Fülle an Informationen. In einer klassischen Geschichtswissenschaft sind diese Tools vollkommen ausreichend, um eine qualitativ hochwertige Arbeit anzufertigen. Darüber hinaus gibt es aber noch ein weiteres Feld, in dem viele Historiker derzeit noch nicht bewandert sind: Es heißt Big Data.
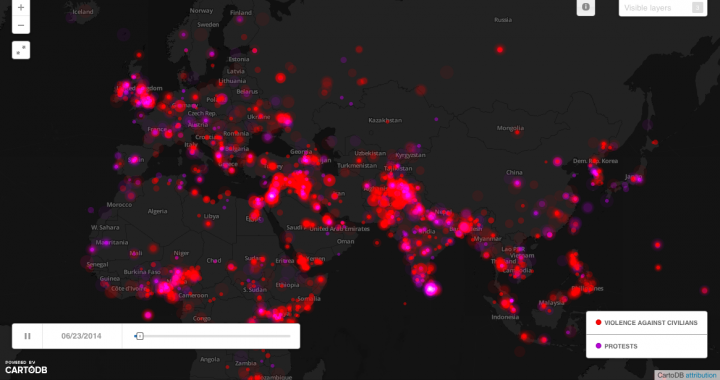
Mit der Bedeutung von Big Data für den Historiker beschäftigt sich der Tech-Journalist Rory Cellan-Jones in einem kürzlichen erschienen BBC-Artikel. Ausgangspunkt war für ihn die Studie von Kalev Leetaru, einem Spezialisten für Big Data an der Georgetown University. In historischen Daten Muster zu erkennen, die dem menschlichen Auge verborgen bleiben, das ist der Traum von Leetaru. Die Software, die er dafür verwendet hat, ist durchaus interessant. Das Tool heißt Google Big Query und ist in der Lage, extrem große Mengen an Daten zu sammeln und aufzubereiten. Kalev Leetaru sichtete Daten bis zum Jahr 1979 und speiste sie in die Software ein. Für letzten 35 Jahre und für die Zukunft übernahm die Software GDLET die Arbeit, indem sie Daten aus verschiedenen Quellen sammelte und strukturierte – von Medienberichten über Wirtschaftsstatistiken bis hin zu Regierungserklärungen in über 100 Sprachen. Was Leentaru mit Hilfe der Software in den Daten sah, sind wiederkehrende Muster. So analysierte er die Ereignisse in der Ukraine, Ägypten und den Libanon und behauptet, Gemeinsamkeiten festzustellen. Ein gutes Beispiel hierfür ist eine Karte, auf der zwei Faktoren in ihrer zeitlichen und räumlichen Entwicklung dargestellt werden: Gewalt gegen die Zivilbevölkerung und Demonstrationen. Leetaru geht aber noch einen Schritt weiter. Er behauptet, den späteren Verlauf der Ereignisse mit den zuvor gewonnen Daten bestimmen zu können, wie er in sinem Blog darlegt. So braucht es nur extrem viele Daten, etwas Statistik und einen guten Algorithmus und schon können wir Weltgeschehnisse besser einschätzen. In nur 2,5 Minuten, so heißt es, wäre es möglich, eine ganze Liste von Perioden in der “World History” der letzten 35 Jahre darzustellen, die Ähnlichkeiten zu den zentralen Monaten der Revolution in Ägypten aufweisen. Der Rest sind Korrelationen. Für die Auswertung braucht es mehr als nur Anfängerwissen in Statistik.
Was bedeutet diese Entwicklung für Historiker? Natürlich werden wir nicht ersetzt. Es werden aber unsere bisherigen Methoden und Herangehensweisen in Frage gestellt. Besonders interessant ist dies vor allem für Zeithistoriker und Historiker der “World History”. Hier werden in den letzten Jahrzehnten eine Unmenge von Daten gesammelt, die digital zur Verfügung stehen. Es sind Tools notwendig, um eine erste Selektion vorzunehmen. Algorithmen können dabei ein Hilfsmittel sein, um Trends zu erkennen, ohne die qualitatative Analyse der Quellen aufzugeben. Auch große Datenmengen müssen im Vorfeld systematisiert werden, ebenso wie das Ergebnis der Software einer historischen Deutung bedarf. Das ist und bleibt die Aufgabe gut ausgebildeter HistorikerInnen und kann durch keinen Computer ersetzt werden. Voraussagen für die Zukunft überlassen wir aber vielleicht besser der Software.
Die dahinterliegende Debatte, ob die Maschine den Menschen eines Tages ersetzen werde, reicht hingegen weiter zurück. Im zweiten Teil, der in wenigen Tagen folgt, wird diese Debatte eingeordnet in die längeren Linien der Computerisierung und der Debatte um künstliche Intelligenz.
Autoren: Janine Noack, Martin Schmitt
Bildquelle: Screenshot des GDELT Global Conflict Boards